|
I'm a Member of Technical Staff at Amazon AGI Labs, researching and building reliable computer-use agents. I graduated with my Master of Science in Computer Vision (MSCV) at the Robotics Institute, Carnegie Mellon University (CMU), where I was advised by Prof. Deva Ramanan. My research at CMU focused on extending panoptic segmentation into the open world and discovering novel objects without explicit supervision. I am fortunate to have received mentorship at every step of my journey. If you think I can help you, please reach out!
Email | Resume | Google Scholar | LinkedIn | Twitter |

|
|
|
|
|
|
|
|
|
|
|

|
[YouTube] [Spotify] [Apple] [LinkedIn] Exploring how agents learn through structured experience. |
|
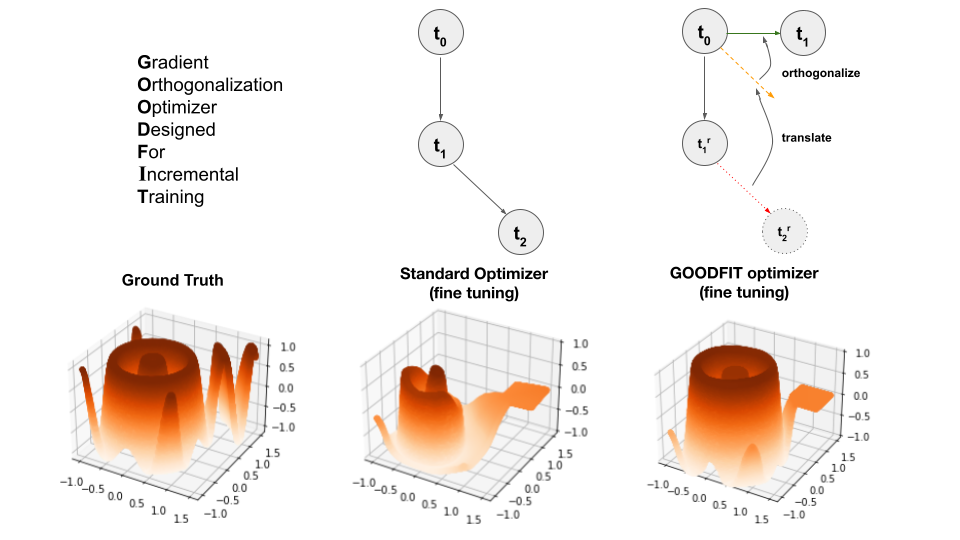
Anirudh Chakravarthy, Shuai Kyle Zheng, Xin Huang, Sachithra Hemachandra, Xiao Zhang, Yuning Chai, Zhao Chen Conference on Neural Information Processing Systems (NeurIPS), 2025 [arxiv] [project page] [project page] [poster] The fine-tuning of pre-trained models has become ubiquitous in generative AI, computer vision, and robotics. We present PROFIT, the first optimizer designed to incrementally fine-tune converged models on new tasks and/or datasets. |
|
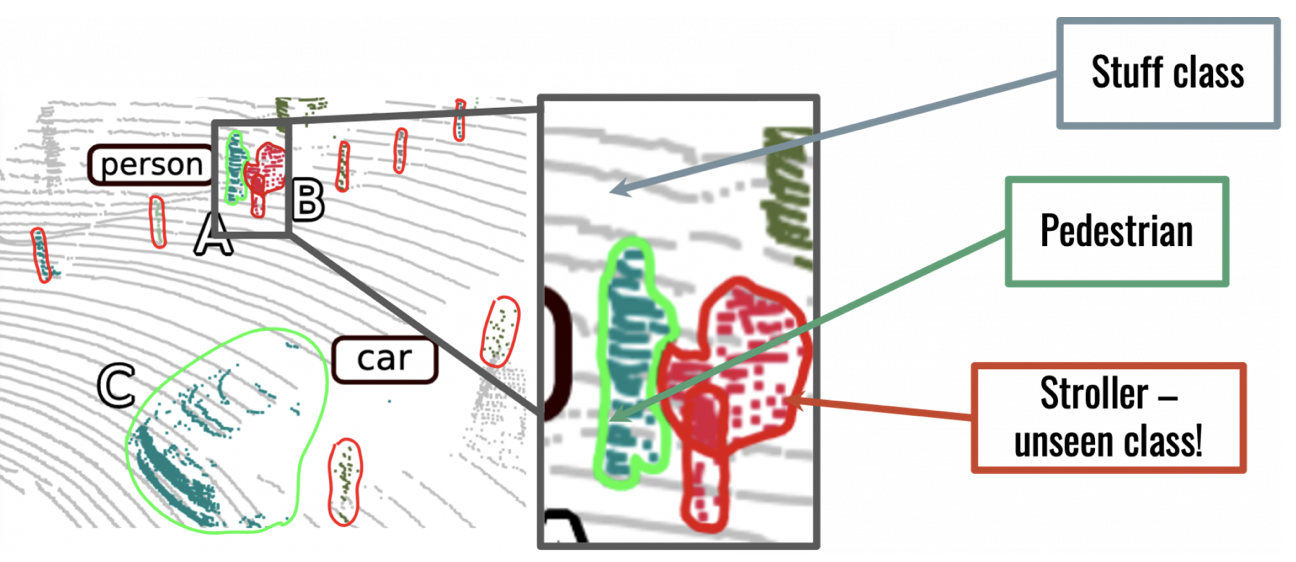
Anirudh Chakravarthy, Meghana Reddy Ganesina, Peiyun Hu, Laura Leal-Taixé, Shu Kong, Deva Ramanan, Aljosa Osep International Journal of Computer Vision, 2024 [pdf] [arxiv] [project page] [code] Current Lidar Panoptic Segmentation (LPS) methods make an unrealistic assumption that the semantic class vocabulary is fixed in the real world, but in fact, class ontologies usually evolve over time as robots encounter instances of novel classes. To address this unrealistic assumption, we study LPS in the Open World (LiPSOW). |

|
Donglai Wei, Siddhant Kharbanda, Sarthak Arora, Roshan Roy, Nishant Jain, Akash Palrecha, Tanav Shah, Shray Mathur, Ritik Mathur, Abhijay Kemkar, Anirudh Chakravarthy, Zudi Lin, Won-Dong Jang, Yansong Tang, Song Bai, James Tompkin, Philip H.S. Torr, Hanspeter Pfister IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [project page] [pdf] We introduce a new dataset and benchmark, YouMVOS, for multi-shot video object segmentation. |

|
Anirudh Chakravarthy, Won-Dong Jang, Zudi Lin, Donglai Wei, Song Bai, Hanspeter Pfister IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2021 [pdf] [arXiv] [code] We identify mask quality as a bottleneck for video instance segmentation. To overcome this, we propose an attention-based network to propagate missing object instances. Our method significantly outperforms previous state-of-the-art algorithms using the Mask R-CNN backbone, by achieving 36.0% mAP on the YouTube-VIS benchmark. |
|
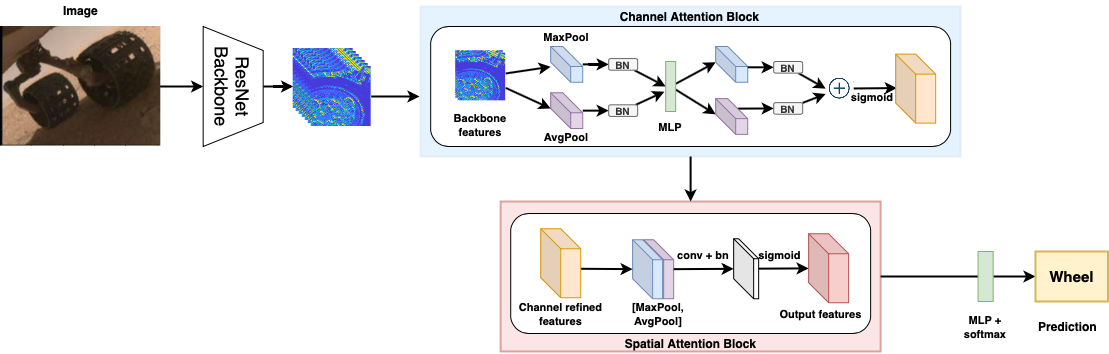
Anirudh Chakravarthy*, Roshan Roy*, Praveen Ravirathinam* IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2021 [pdf] [code] We propose a network, MRSCAtt (Mars Rover Spatial and Channel Attention), which jointly uses spatial and channel attention to accurately classify images. We use images taken by NASA's Curiosity rover on Mars as a dataset to show the superiority of our approach by achieving state-of-the-art results with 81.53% test set accuracy on the MSL Surface Dataset, outperforming other methods. |
![[poster]](https://neurips.cc/media/PosterPDFs/NeurIPS%202025/117387.png?t=1764606396.4137552){kind=link}
|
|
|
|
Member of Technical Staff Present Computer-use Agents (check out Nova Act!) |
|
|
Senior Applied Scientist Large Models for Long-tail Perception |
|
|
Research Intern Video Instance Segmentation |
|
|
Research Intern Vital Parameter Estimation |
|
|
|
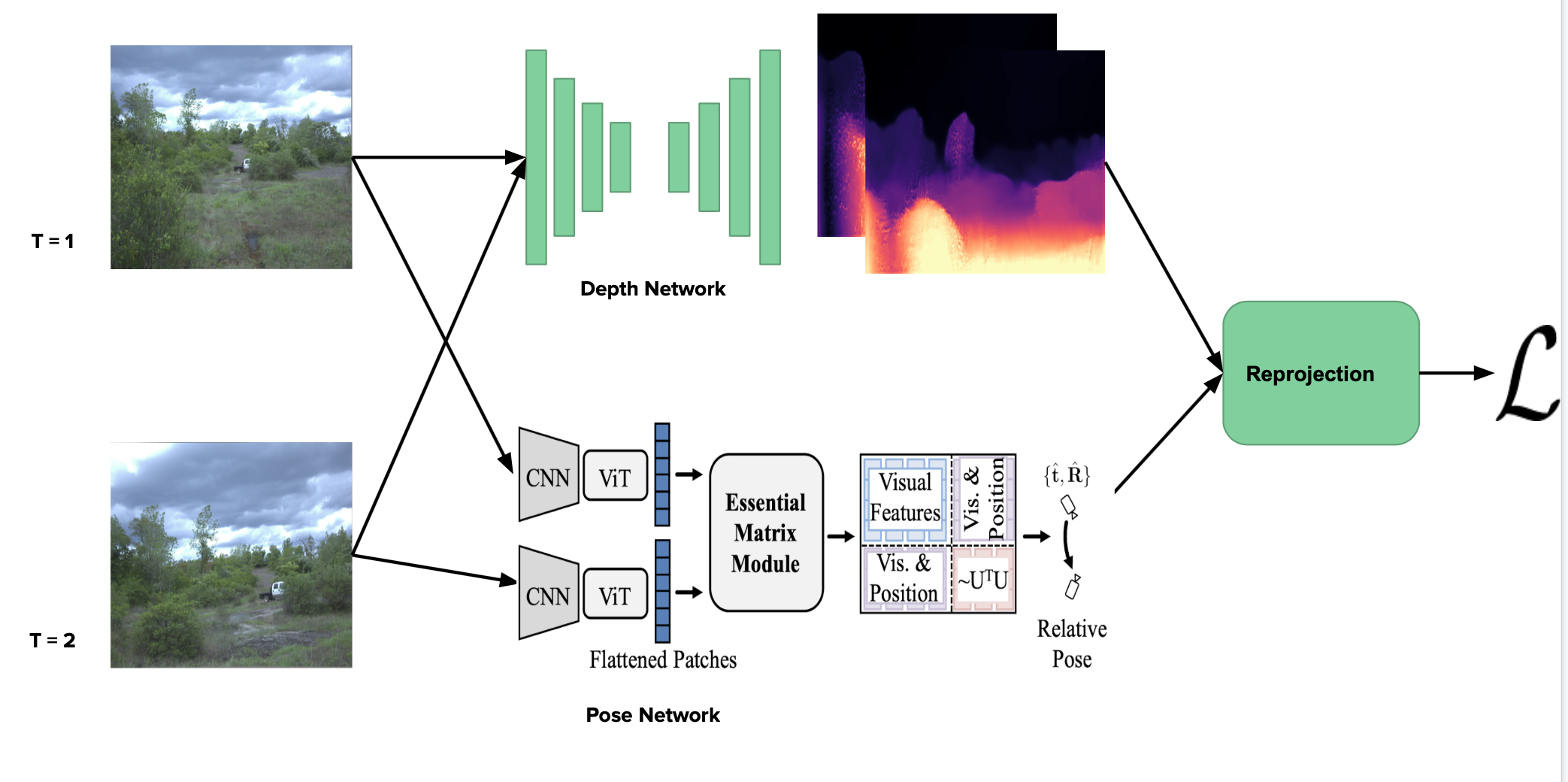
[pdf] [code] Existing camera pose estimation methods make use of ground-truth odometry as supervision, which may be expensive to obtain. In this work, we train a transformer-based pose estimation network in a self-supervised manner, leveraging advances in monocular depth estimation. |
|
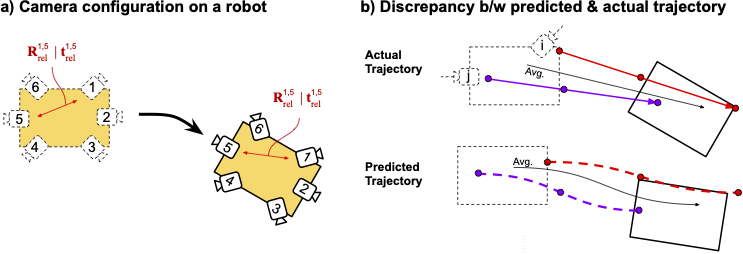
[pdf] [code] For visual localization, we often have multiple cameras mounted onto a robot which can be used to infer odometry (known as multi-view visual odometry). Existing works either heavily rely on the scene geometry or use complicated networks posing challenges for real-world generalization. In this work, we aim to develop simple yet strong baselines for multi-view visual odometry, by fusing estimates using monocular visual odometry. |
|
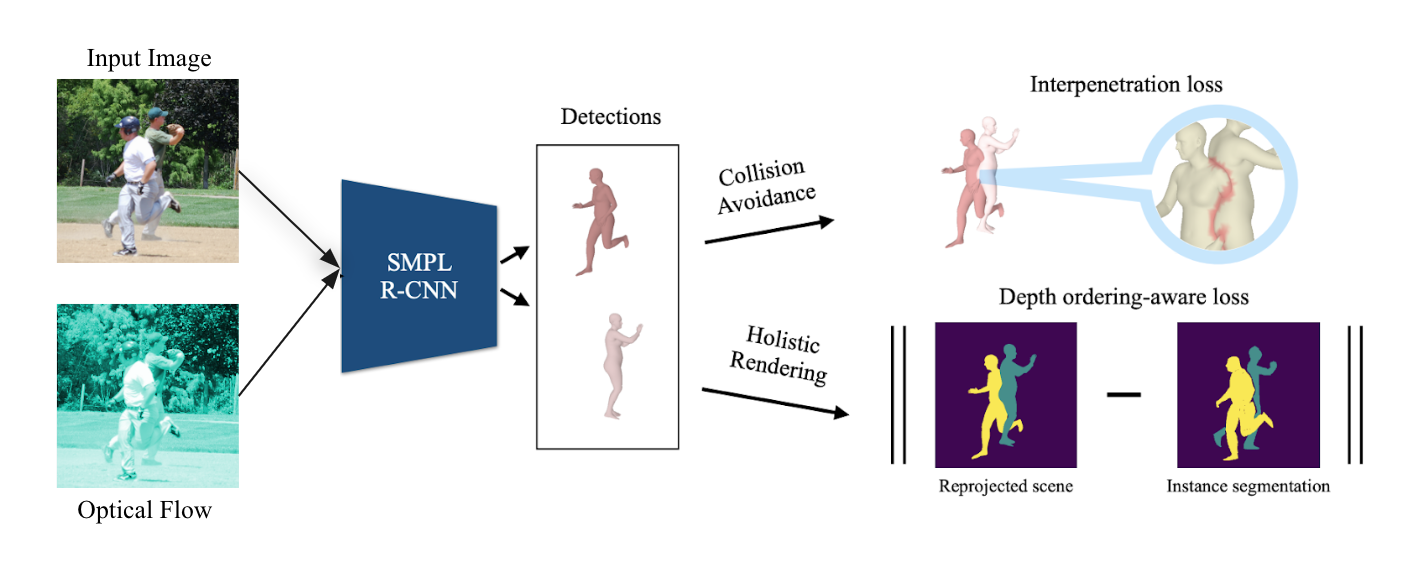
[pdf] [code] Multi-person 3D reconstruction is challenging, yet no prior work aims to disambiguate inter-person occlusions using temporal information. Motivated by this, we leverage optical flow as a cue to improve 3D human pose estimation in crowded scenes. |
|
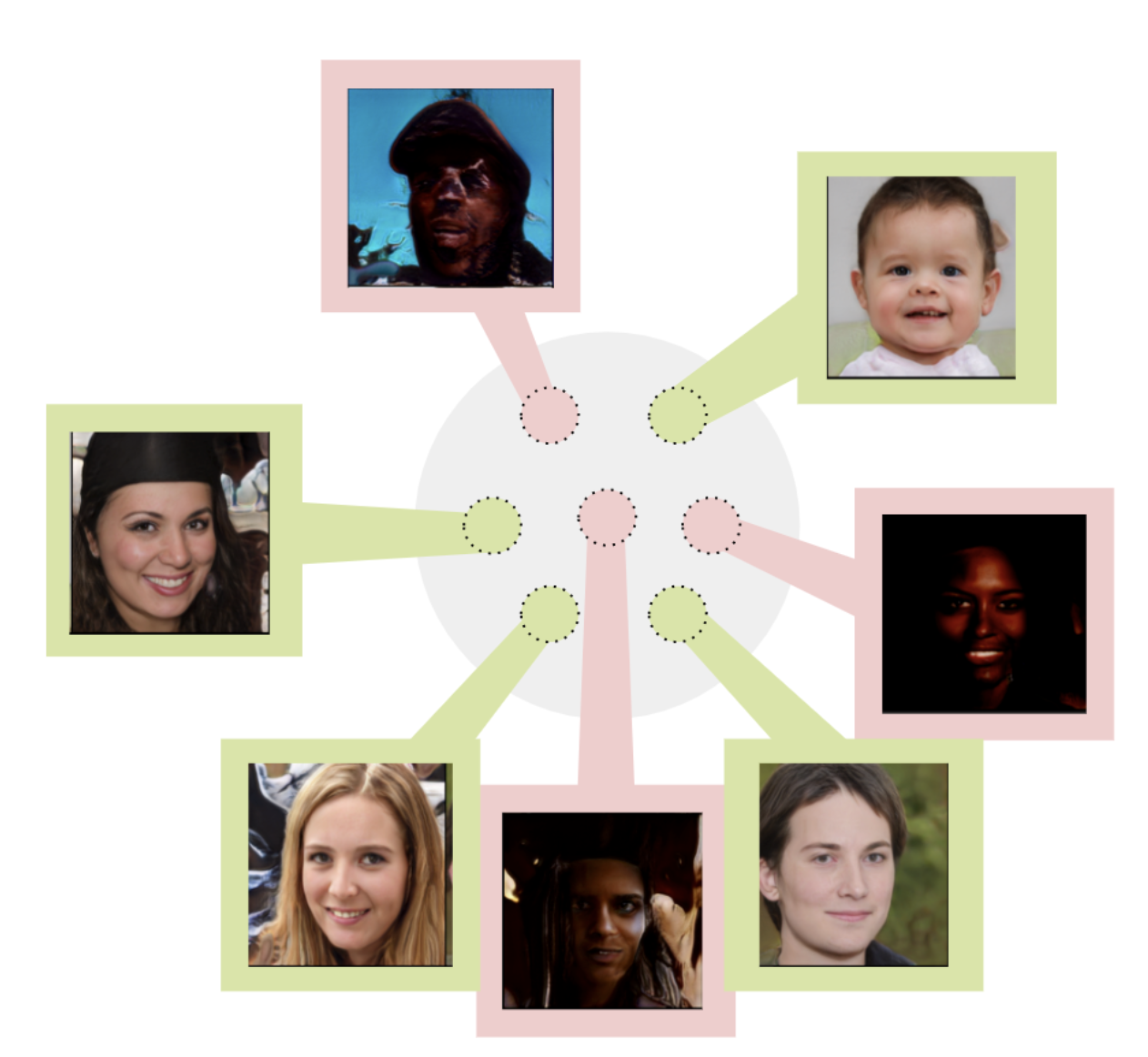
[project page] [code] Generative models such as StyleGAN have shown very promising results. However, while using such GANs for face generation, we often encounter cases of non-photorealistic generations (e.g: artifacts, not face-like, etc.). In this project, we aim to formally establish the existence of such failure modes in GANs. |
|
Source code from Jon Barron
|